Hipertexto: cómo la ficción se hizo realidad
 Imagen generada con Runway AI de acuerdo sus condiciones
Imagen generada con Runway AI de acuerdo sus condiciones
Hace unos años, estaba en una reunión de trabajo, en una de esas infaltables capacitaciones sobre planificación, cuando el experto que dirigía el evento nos instruyó que hagamos dos trabajos prácticos: una planificación general, anual, de actividades, de la que debíamos desglosar planificaciones semanales e, incluso diarias 😵💫. En mi laptop, tenía abiertos tres documentos de texto, uno para cada nivel del plan y, mi calendario-agenda, en el administrador de correo, para hacerme una idea general del tiempo de esos planes; mientras que un colega mío, solo ejecutaba Notion en su MacBook para realizar la misma labor y, así se mantuvo mientras trabajamos en ello, es decir, hizo todo el trabajo práctico sin salir de esa aplicación 😎. Yo, que soy un curioso infatigable de la ofimática y, me encanta aprender novedades sobre esa área, no me cohibí de preguntar a mi compañero de dónde había salido semejante peculiaridad. Ya aprendido el nombre del programa, en mis tiempos libres, mientras duraba ese evento, me puse a investigar de qué se trataba ese artilugio. Al enterarme de todas sus funciones quedé bastante impresionado.
Notion es un programa para tomar notas, pero, no se queda allí, sino que es mucho más ambicioso: las notas pueden adquirir varias funcionalidades, desde tablas, casillas de verificación, inserción de enlaces y archivos adjuntos, etc.; además, pueden relacionarse unas notas con otras mediante hipervínculos, permitiendo indexarlas de varias formas a partir de etiquetas y; por si eso fuera poco, permite compartir o, incluso, publicar, esos trabajos en forma de portales (si se quiere, convertirlos en páginas web 😯) y, trabajar de forma colaborativa con otros usuarios. Es como si los creadores de Notion, después de haber tenido una pesadilla compartida, hubieran decidido que no necesitamos nada más en esta vida que una libreta de anotaciones, convirtiéndola, literalmente, en una oficina completa, evitando de esta manera, no solo que alguna vez osemos salir del ordenador, sino, incluso, de su propia, pequeña y hegemónica ventana. Y es que, pensándolo bien, lo que en realidad está haciendo Notion es aplicar la idea de hipertexto a nuestra gestión del conocimiento personal y social, algo que, si bien, no es novedoso, probablemente no había estado tan extendido en la vida profesional digitalizada.
Desarrollemos esa idea: si un texto, es un documento escrito, un hipertexto es un texto que contiene enlaces a otros textos, pero, con "enlaces" no se expresa simplemente la indicación de referencias a otros documentos, como de forma clásica se hace en los ensayos académicos, por ejemplo, sino que, el texto al que se apunta, debe ser inmediatamente accesible por la persona que consulta el texto original. Se acabaron las consultas posteriores en la biblioteca de otra ciudad. En una época en la que el propio internet, es decir, la World Wide Web, está construido bajo el concepto de hipertexto, esta idea probablemente no nos sorprenda en lo más mínimo, tomando en cuenta de que ya estamos acostumbrados a hacer clic en el enlace de una página y obtener, inmediatamente, el documento citado; Wikipedia, es posiblemente el caso más emblemático: la enciclopedia de hipertexto más grande del mundo y, además, de la historia de la humanidad.
Volviendo a la historia del inicio, es necesario aclarar que este escrito no es una publicidad para Notion, aunque así lo parezca ahora, de hecho, no uso ese programa y luego explicaré por qué; sin embargo, desde que conocí su funcionalidad, quedé bastante sorprendido y, me propuse comprender cómo es que las clásicas técnicas de estudio, surgidas en paralelo a la escritura, fueron evolucionando a lo largo de las épocas hasta alcanzar estas complejas herramientas ofimáticas instaladas actualmente en nuestros ordenadores. Al verme abrumado con esa información, no encontré otra solución que ordenarla y publicarla en este blog 🤷; al final, como es mi costumbre, evalúo estos avances en mi propio proceso académico y productivo. Por tanto, este escrito recorre los orígenes del hipertexto, desde el formato analógico al digital, a partir de la inspiración surgida en la ficción literaria, pasando por los métodos de tomar apuntes y organizarlos, de acuerdo a distintas categorías; luego, se revisa cómo estas tendencias son introducidas en los sistemas informáticos; para, finalmente, evaluar todos estos aspectos desde mis prácticas personales y; extraer conclusiones de todo lo reseñado.
Ficción hipertextual
Existe un artículo, escrito en 1987, por Jay David Bolter y Michael Joyce, los desarrolladores de Storyspace™, un programa para crear narrativas hipertextuales, que al ensayar una breve historia del hipertexto propusieron que esta idea surgió inicialmente en la ficción, como una fantasía curiosa, bajo las bases de la literatura experimental de principios del siglo XX, desde corrientes como el modernismo o el dadaísmo. Esta idea es repetida actualmente en las entradas de Wikipedia que desarrollan el término, sin embargo, posteriormente, se demostrará en este escrito, que si bien, la literatura posiblemente inspiró de forma muy importante la materialización del hipertexto en la informática, no es de ninguna manera su único antecedente, existiendo aportes importantes, incluso más antiguos, desde la bibliotecología.
Continuando con la idea de estos autores, debe tomarse en cuenta que el soporte dominante para almacenar el conocimiento escrito, durante la citada época, era el papel, ya sea de forma manuscrita o impresa. Esta nueva literatura, estaba interesada en romper con el paradigma narrativo clásico, expresado en la secuencia lineal de eventos, construidos solo desde la perspectiva de un narrador omnipresente, bajo el esquema de: presentación, nudo y descenlace. Un ejemplo de ruptura con este modelo sería la aparición de historias fragmentadas en narraciones contradictorias de un mismo evento, desde el punto de vista de los personajes o, incluso, temporalidades desordenadas de ese mismo evento, además de lo anterior, en cuyo caso, el lector, jugaría un papel mucho más activo al intentar armar este "rompecabezas" y descifrar la trama y su significado, donde al final, múltiples interpretaciones serían posibles.
En este ejercicio, ya se pueden entrever las bases que permiten la transición del texto al hipertexto: el texto, debido a las limitaciones del formato impreso, presenta su contenido de forma secuencial, al modo de la narración clásica, esto debido, entre otras razones, a las limitantes del formato escrito; al experimentarse con la ruptura de esa tradición, evitando la secuencia lineal y la voz autoral en la trama, se abre la puerta a la experimentación con otros formatos, aunque sea de forma fantasiosa y, sobre el propio formato impreso.
Los autores anteriormente mencionados, Bolter y Joyce, citan dos obras literarias como las impulsoras iniciales de este concepto, aunque sea, como se dijo, desde el plano de la ficción. En este caso, hacemos referencia a dos cuentos del escritor argentino, Jorge Luis Borges, titulados: "Examen de la obra de Herbert Quain" y "El jardín de los senderos que se bifurcan". Ambos cuentos, si bien, son narrados desde la perspectiva de un personaje y, en el caso de la segunda historia, la causalidad y temporalidad de los sucesos pueden tener diferentes interpretaciones, no son estos elementos narrativos transgresores los que identifican a estas obras como introductoras del concepto del hipertexto, sino que en ambas, el narrador, reseña una obra ficticia que claramente intenta hacer realidad una obra de hipertexto, a pesar de las limitaciones del formato impreso.
El primer caso, "Examen de la obra de Herbert Quain", constituye una falsa reseña de la obra de un autor ficticio, cuyas publicaciones son de lo más descabelladas. Una de ellas, llama la atención porque, precisamente, representa la encarnación del hipertexto: se trata de una novela de 13 capítulos, de entre los cuales, no solo hay narraciones testimoniales, desde distintas temporalidades de un evento, sino también, bifurcaciones de los hechos, es decir, otras posibilidades de ciertos sucesos. De las combinaciones de esa estructura, se puede extraer, supuestamente: nueve novelas, de tres capítulos cada una, en los que se encuentran los géneros más diversos 😁. En ese sentido, el falso cronista califica semejante obra como "regresiva y ramificada". El segundo caso, "El jardín de los senderos que se bifurcan", es un cuento, podría decirse, de género policial, además de que representa una historia más compleja que la anterior, en el centro de la trama, se reseña una obra, también fantástica, que es la viva proyección del hipertexto. El antepasado del protagonista, un profesor de origen chino de nombre Yu Tsun, llamado Ts'ui Pên, se propuso en vida dos labores: escribir una novela de complejidad nunca antes vista y, construir un laberinto donde "se perdieran todos los hombres". Habiéndose propuesto esto, hasta fallecer en ese intento, además, en aislamiento de la sociedad, la familia del difunto solo encontró entre sus posesiones una extensa cantidad de manuscritos diversos y contradictorios y, sin ninguna señal del laberinto prometido, llegando a pensar, por tanto, que el autor había enloquecido. Luego, en el cuento, se revela que su obra fue malinterpretada y que, en realidad, novela y laberinto eran una sola obra y, aquellos, aparentemente, incoherentes textos, conformaban una narración en la que se representaban bifurcaciones, no del espacio, al modo del laberinto, sino del tiempo, presentando una compleja red de encrucijadas y convergencias de eventos, que incluso, terminan dando sentido a la, hasta ese momento, confusa narración de Borges.
A los mencionados autores del considerado como, primer programa de computadora para la escritura de novelas de hipertexto, Storyspace™, Jay David Bolter y Michael Joyce, les llama poderosamente la atención, en su ya citado artículo, que Borges se limite a imaginar estos experimentos literarios en vez de ejecutarlos. Luego de elaborar este razonamiento, los desarrolladores concluirán que esto se debió a que, mientras escribía estas fantasías, Borges no tenía los medios tecnológicos que le permitan hacer realidad esa empresa:
Borges never had available to him an electronic writing space, in which the text can constitute a network of diverging, converging and parallel times (p. 46).
Personalmente, me pregunto si, de haber poseído los medios tecnológicos de ahora, Borges habría decidido empeñarse en semejante emprendimiento; tengo razones para suponer que no. Probablemente, el hecho de que el autor presentara al hipertexto en el marco de una curiosa fantasía, se deba a otros motivos más profundos que la inexistencia del soporte tecnológico para lograr aquello, incluido, a mi criterio, un posible escepticismo ante la materialización de tal propósito, por rimbombante e innecesario; recordemos que los personajes ficticios que desarrollan estos proyectos, en sus cuentos, son difuntos incomprendidos y desventurados, a pesar de su genialidad. Retomaré esta idea posteriormente en este escrito, porque, ciertamente, permite más desarrollo.
Lo interesante de esto, por cierto, es que el programa creado por esos autores, permitió, tal y como ellos esperaban, la materialización de novelas de género hipertextual, siendo este un acontecimiento primigénio en la historia. Los textos fueron publicados en formato digital y, tuvieron relativo éxito publicitario entre 1987 y finales de la década de 1990, gracias a programas de computador privativos como, el mencionado Storyspace™ e, HyperCard™, ambos lanzados para el entorno Apple Macintosh y que permitían crear estas obras. Se suele indicar como una novela pionera en este género a "Afternon, a story" (1987) de, Michael Joyce, uno de los autores del anterior artículo, la cual, todavía en la actualidad, se la puede adquirir mediante compra. Algunas de estas obras están, en este momento, publicadas de forma gratuita en internet: es el caso de: "Victory Garden" (1991), de Stuart Moulthrop y, "The unknown" (1999), de William Gillespie. Una novela en español, que trasciende del hipertexto a la hipermedia es "Golpe de gracia" (2007) de Jaime Alejandro Rodríguez.
Es interesante destacar que en este periodo, uno de los autores anteriormente mencionados, Stuart Moulthrop, se propuso, a finales de la década de 1980, la descomunal tarea de materializar la laberintica novela de Ts'ui Pên, que Borges reseñó desde la ficción. Bolter y Joyce, anteriormente citados, describirán de la siguiente manera la complejidad de ese trabajo:
This Storyspace module contains a web of over 100 units and 300 connections. Moulthrop has added his own meditions to those of the Borges’ story (p. 46).
Al parecer, ese proyecto solo se halla disponible para su consulta en los archivos de la Universidad de Yale.
Desde la primera década del 2000 hasta la actualidad, hubo una segunda ola de narrativas hipertextuales, esta vez creadas con un programa de código abierto llamado Twine y, en varios casos, publicadas de forma gratuita. Me llaman la atención: "The Uncle Who Works for Nintendo" (2014), de Michael Lutz y, "You Are Jeff Bezos" (2018), de Kris Ligman.
Es interesante constatar en este punto, que la ficción hipertextual no es un género literario que precisamente haya estado entre los más populares a lo largo de los años. Aquí cabría analizar que, a diferencia de lo que deseaban los creadores de Storyspace™, en el artículo anteriormente citado, respecto a que las narrativas hipertextuales logren trascender de forma exitosa el ámbito de los videojuegos (estamos hablando de 1987), en realidad, lastimosamente, la relación de estas dos industrias, actualmente, se mantiene en una proporción similar a la de esos días, continuando la hegemonía de los videojuegos, ahora, en línea. Aquí es interesante añadir también que, el creador del término hipertexto, Ted Nelson, se quejaba, en 1992, de la incorrecta forma de referirse a formatos visuales con posibilidad de interacción del usuario, como los videojuegos, en este caso, como "interacción multimedia", cuando el término correcto es hipermedia.
Con los recientes avances en tema de inteligencia artificial (IA) y, la realidad virtual o aumentada, esto adquiere otras dimensiones. Bolter y Joyce, citados previamente, fantaseaban en 1987, con que la computadora no solo recuerde las decisiones tomadas por el usuario mientras se bifurcaba en las posibilidades de la trama de una novela de hipertexto, sino que, más bien, pueda generar nuevas oraciones en respuesta a las inquisiciones del usuario, tal y como hacen los modelos de IA en la actualidad:
The computer can also keep track of the previous episodes the reader has visited, so that he may be barred from visiting one episode before he visits another. Artificial intelligence experts would not consider such a simple scheme for interactive fiction worth pursuing. They would argue that we have to store knowledge representations in the computer and write a program that can generate new sentences in response to the reader’s replies. In other words, the program itself would be the author, not simply the medium for delivering what the human author has written. While this AI strategy is interesting, it is not feasible at present or in the near future (p.42).
Si ahora se le añade a esto los avances que se están realizando en el área de la realidad virtual, aumentada, o "metaverso" y, se le incorpora las innovaciones aportadas por las densas y envolventes narrativas de los estudios de videojuegos, ya se puede vislumbrar que existirá una posible fusión de lo que ahora se conoce como cine, con los juegos de video e, incluso, redes sociales, hipermedia y demás, tal y como se proyecta en la película de Steven Spielberg "Ready Player One" de 2018.
Anotaciones, informática e hipertexto
Formas analógicas
Volviendo al inicio de este tema, las anotaciones, es interesante evaluar su evolución a lo largo de la historia. Es decir, una vez creada la forma de comunicación escrita, el proceso de materializar símbolos está fuertemente relacionado con el soporte tecnológico que acompaña ese fin. En épocas antiguas, este procedimiento estaba bastante limitado debido a las dificultades para llevarlo a cabo, ligadas principalmente a los materiales de archivo, en cada caso: arcilla, piedra, cueros, papiros, etc. En la Edad Media, gana protagonismo el uso de la tinta y la elaboración de papel artesanal, de acuerdo a los procedimientos importados del Asia y, se difunde e, incluso, institucionaliza, esta práctica, a partir de la combinación de ambos componentes. La difusión del conocimiento a través de libros impresos, desde la época renacentista, permiten, probablemente, diferenciar más claramente la publicación de una obra escrita, revisada, corregida, perfeccionada, diagramada, en oposición a los simples apuntes que toma el receptor de ese mensaje impreso, sin la intención de publicar esos pensamientos, sino, emitir meras anotaciones personales, muchas veces, incluso hechas en los márgenes de esas obras publicadas.
Es, a partir de este hipotético hito histórico, entre el Renacimiento y la Ilustración, que comienza a producirse una sistematización en este ámbito. Surgen distintas aproximaciones para organizar notas, por ejemplo, el archivador de hojas de papel de Vincent Placcius, que, perfeccionando la idea inicial de Conrad Gessner, permite archivar notas manuscritas de forma ordenada, fijadas a partir de ganchos metálicos. Es a partir de este invento que surgen otros aportes, como el de Carl Linneaus, en el siglo XVIII, los cuales, van aproximándose más al actual concepto de ficha bibliográfica. Debe comprenderse que posteriormente a esto, se va posicionando el método científico, primero, en las élites académicas y, luego, poco a poco, en la vida cotidiana del mundo occidental. Al intensificarse más estas ideas, podría entenderse que en paralelo a la Revolución Industrial, se impone la necesidad de producir un conocimiento sistemático para monitorear los complejos procedimientos económicos y tecnológicos que se llevaban a cabo, sobre todo, desde las esferas de gestión de esas relaciones, entonces, esto impulsaría también necesarios métodos de manejo de información masiva y enrevesada.
 En la imagen se aprecia una ilustración, realizada por el propio Vincent Placcius, de su sistema de acopio de notas. Imagen de dominio público.
En la imagen se aprecia una ilustración, realizada por el propio Vincent Placcius, de su sistema de acopio de notas. Imagen de dominio público.
Ya en el siglo XX se perfeccionan las anteriores propuestas de gestión de notas y se les añade el concepto de hipertexto. Habiéndose difundido distintos métodos de archivo de fichas bibliográficas y ya existiendo una tradición de ordenamiento de notas bibliográficas, se populariza el concepto alemán de zettelkasten o, caja de notas, que es un sistema que combina los conceptos de hipertexto y metadatos en la tarea de organizar notas. Las hojas individuales de papel poseen unos encabezados donde quedan registradas etiquetas que reflejan aspectos importantes de la nota, para que de este modo, el investigador, pueda vincular unas notas con otras y obtener así un panorama sistematizado de la materia que estudia. Es interesante como en este ejemplo se desarrolla el concepto de metadatos, tan utilizado en informática en estos días. Se define a los metadatos como "datos que proporcionan información acerca de otros datos". En este caso, las etiquetas que se añaden a las notas no solo proporcionan información necesariamente ligada al contenido de las notas, sino, que al vincularse con otras, crean nuevo conocimiento, tendencias y síntesis, por ejemplo. Dos famosos pensadores que utilizaban esta forma de almacenar sus notas personales eran el filósofo argentino Mario Bunge y el sociólogo Niklas Luhmann.
Finalmente, es interesante observar como terminamos ligando la toma de apuntes o, notas, con la organización bibliográfica, base del mundo académico y, dejamos de lado los sistemas de anotaciones relacionados con el mundo productivo. Es importante adentrarse también en este nicho, porque el software que reseñaremos posteriormente, no solo está basado en la idea de hipertexto, sino también en sistemas de organización de tareas con base en la disponibilidad de tiempo. Entre el siglo XX y comienzos del siglo XXI, dentro de las muchas propuestas de gestión de tiempo, se popularizan dos sistemas que luego se verán reflejados en el software de toma de notas en forma de tareas: el denominado, método Einsenhower y; el sistema productivo Getting Things Done del consultor productivo David Allen.
El "método" Eisenhower, curiosamente, se basa en una frase pronunciada por el expresidente estadounidense, Dwight D. Eisenhower, mientras ejercía el cargo, en un discurso otorgado en la Asamblea del Consejo Mundial de Iglesias, en 1954, en el que citaba la frase de otro expresidente, al que, de forma llamativa, no nombra, pero que supuestamente habría dicho: "I have two kinds of problems, the urgent and the important. The urgent are not important, and the important are never urgent". A partir de esa penetrante frase, el pensador empresarial Stephen Covey, construyó en su libro, "Los 7 hábitos de las personas altamente efectivas", la denominada "matríz de decisión de Eisenhower", la cual, establece que las tareas urgentes e importantes, al mismo tiempo, deben hacerse inmediata y personalmente; las que son importantes, pero no urgentes, deben tener una fecha de finalización y, hacerse personalmente; las que no son importantes, pero son urgentes, deben ser delegadas y; finalmente, las que no son importantes, ni urgentes, deben ser descartadas.
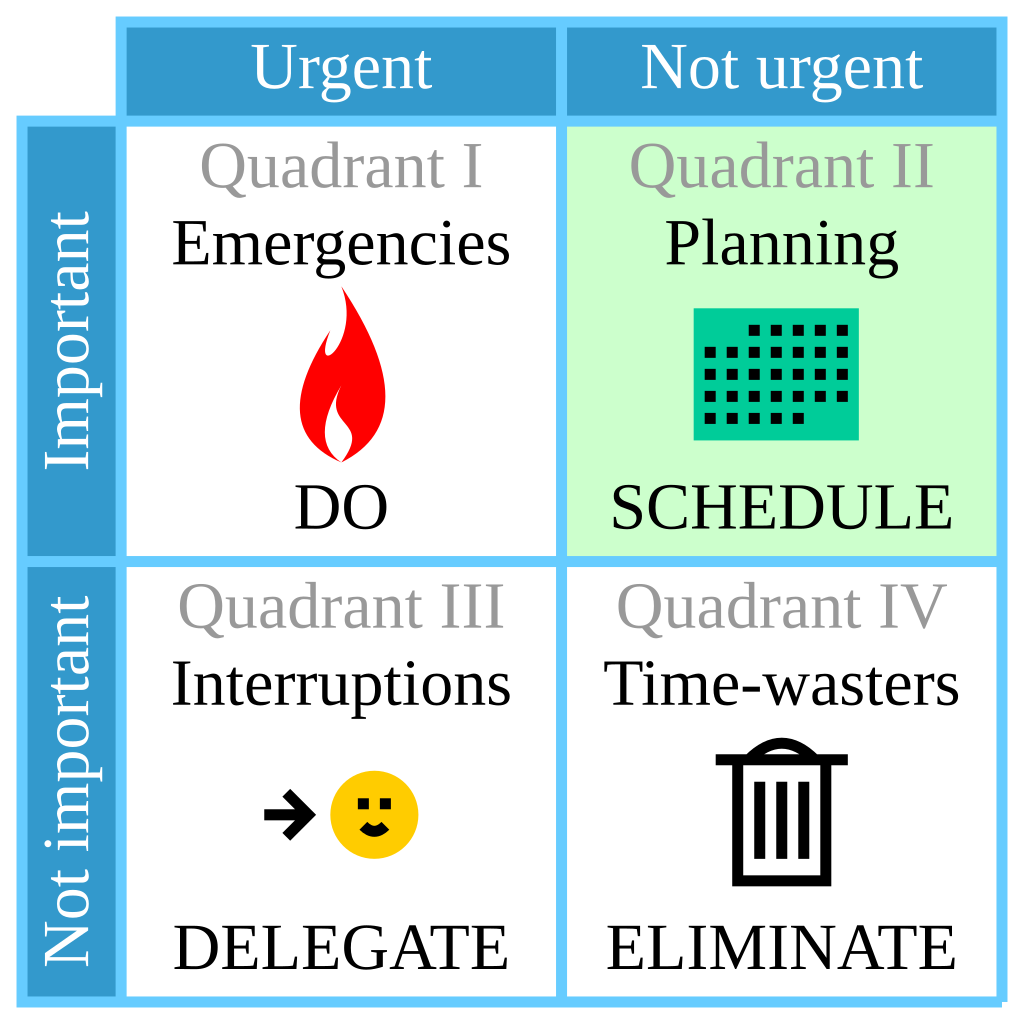 Interpretación ilustrada de la "tabla Eisenhower". Licencia CC BY-SA 4.0.
Interpretación ilustrada de la "tabla Eisenhower". Licencia CC BY-SA 4.0.
Por su parte, el sistema Getting Things Done (GTD), se diferencia del anterior en el sentido de que no se basa en la clasificación de tareas de acuerdo a prioridades, sino, en la delimitación de estas, de un modo concreto y, su organización, a partir de contextos o proyectos, evitando así los bucles indefinidos y el abandono de buenas ideas por pérdida de foco. Este enfoque propone elaborar una lista de tareas y procesarlas de la siguiente manera: si la tarea, no es significativa de un modo concreto para la persona, debe decidirse si desecharla, postergarla o guardarla como referencia; si la tarea, debe realizarse en más de un paso, debe convertirse en un proyecto y; si tiene una fecha de realización, debe agendarse y, si no, asignarle un contexto. Esta descripción es una simplificación extrema de todas las posibilidades que ofrece este sistema y se hace con fines de exposición.
A simple vista, puede que no quede clara la relación de estos sistemas de organización de tareas con el hipertexto, pero, como se apreciará en el apartado informático de este escrito, la organización de las tareas, basándose en estos criterios y, más aún, combinando ambos sistemas, es decir, GTD y Eisenhower, puede llegar a generar un flujo de tareas, clasificadas a base de prioridades, proyectos y contextos, que se bifurcan en una maraña de interminables subtareas.
La era digital
Es curioso verificar la influencia que tuvo la idea del hipertexto en la informática, en general y, finalmente, en los programas administradores de notas, que al fin y al cabo son los que desataron mi interés por este tema. Algo que llama poderosamente la atención es que muy poco tiempo después de la publicación de los dos cuentos de Borges, descritos anteriormente (1941), un ingeniero llamado Vannevar Bush, proyectaba, en 1945, igual que Borges, sin llevar a cabo su idea, una máquina de nombre Memex, que, en teoría, podía poner a disposición del usuario múltiples documentos almacenados en marcos de microfilm, enlazados en cadena. Si bien, este proyecto no se llevó a cabo, por lo complicado del diseño, se lo considera precursor de los posteriores sistemas reales de hipertexto e, incluso, del propio Internet.
A finales de la década de 1960, el ya mencionado creador del término "hipertexto" e "hipermedia", Ted Nelson, desarrolló el considerado como primer sistema de hipertexto funcional, probablemente bajo la influencia de la máquina Memex, pero esta vez, en forma de software, denominado, Hypertext Editing System y, que requería una IBM 2250 para funcionar. Varios fueron los programas que sucedieron a este a lo largo de las décadas, especializándose en diversas tareas y perfeccionando su funcionalidad, incluidas las ya mencionadas aplicaciones para la elaboración de ficciones hipertextuales, hasta que a principios de la década de 1990 se fusionan dos ideas facinantes: existían ya varios antecedentes de sistemas de transmisión de información textual en red, cubriendo grandes distancias, usados por las esferas gubernamentales, pero a esto, ahora, se le añadía el enfoque hipertextual, dando como resultado las bases de la actual y, fundamental, World Wide Web.
Por tanto, desde el ámbito específico de las aplicaciones para tomar y almacenar notas, probablemente estas, en un inicio, no se diferenciaban de los procesadores de texto. Es decir, anteriormente los ordenadores no se utilizaban a través de una interfaz gráfica, entiéndase esto como el espacio de trabajo expresado mediante la figura de "escritorio", con menús desplegables para seleccionar opciones como programas visualizados a través de íconos vistosos; en un formato de "ventanas; creación de "carpetas" para el almacenamiento de archivos; selección de "fondo de pantalla"; etc. Antes, la única forma de interactuar con el ordenador era mediante comandos de texto escritos en la terminal y, tales órdenes eran procesadas inmediatamente, mostrándose los resultados en la pantalla. Además, es importante recordar que el concepto de "computadora personal" o, de "escritorio", no se materializa en el sentido que le damos ahora hasta bien entrada la década de 1970 y, se expande de forma exitosa durante los años 80, por tanto, la idea de "tomar notas" en el ordenador, probablemente no haya sido tan extendida, al ser este todavía de uso comunitario principalmente. En este contexto inicial, las notas, apuntes, recordatorios, de ser realizados en el ordenador, probablemente eran almacenados a través de editores de texto plano, en forma de archivos o, incluso, a través de los primeros programas procesadores de texto enriquecido o formateado, los precursores del actual Microsoft Word, como el extinto WordStar, desarrollado a inicios de la década de 1980 para un entorno no gráfico, por ejemplo, el sistema operativo MS-DOS.
Entonces, en un entorno de desarrollo, todavía básico, de los ordenadores y, ya adoptadas las computadoras personales, se puede imaginar que lo que determinaba la forma en la que la gente almacenaba apuntes en el ordenador, era la ocupación del usuario. En este caso, si el usuario era un desarrollador o programador de aplicaciones, un informático, por ejemplo, es probable que almacenaba sus apuntes en texto plano, a partir de un programa editor de texto (de hecho, los lenguajes de programación permiten almacenar apuntes o comentarios al código fuente, anteponiendo un signo para diferenciar esa función) o, utilizaban procesadores de texto especiales para documentar el desarrollo de sus programas y; si el usuario utilizaba su ordenador para labores de producción, que es el uso más extendido que se le da a estos aparatos, por ejemplo, labores de escritura, contaduría, asistencia empresarial, recepción organizacional, etc., esta labor haya sido improvisada, inicialmente, a partir de procesadores de texto complejo o formateado. Probablemente, aún hoy, con todas las aplicaciones especializadas de notas que existen, esto siga siendo así para muchas personas.
Microsoft Notepad, que es una aplicación de texto plano, es decir, que no admite formateo de texto (digamos letras itálicas, subrayados, tablas, etc.) se lanza oficialmente en una fecha tan lejana como 1983, incluso con la, entonces, novedosa función de uso de mouse, lo que representa una especialización respecto a un programa procesador de texto en sí. Sin embargo, contrario a lo que podría creerse, en una fecha bastante cercana a la mencionada, ya se rastrea un programa diseñado específicamente para tomar notas y, no solo eso, sino con funciones de hipertexto incorporadas. Sí, la idea de Notion no se oye tan revolucionaria después de saber aquello. En 1984 se lanza el programa NoteCards, una "base de conocimiento personal" influenciada claramente por la idea de hipertexto, pero específicamente, por el ya citado método zettelkasten, que en esencia, es un organizador de archivos personales indexados y enlazados entre sí. El programa fue diseñado inicialmente para un ordenador Xerox, pero luego fue exportado a Microsoft Windows e, incluso, estuvo disponible para versiones de Linux.
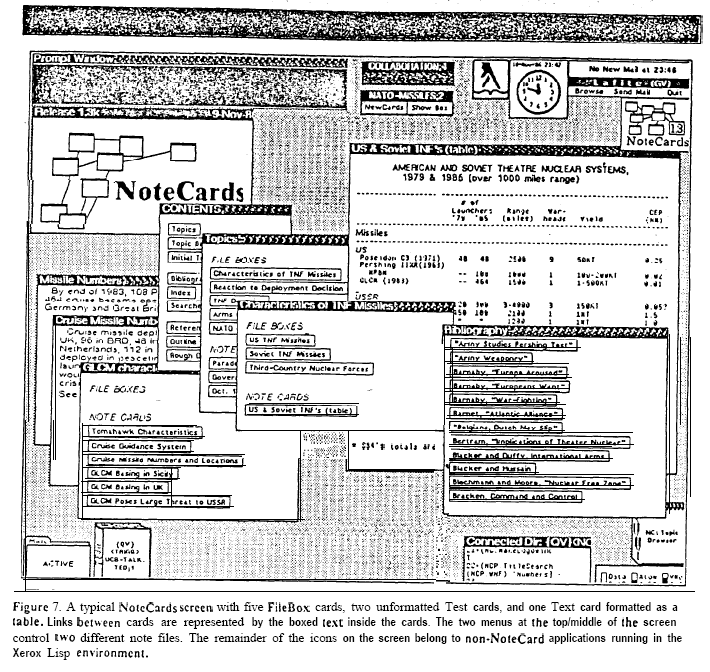 Imagen escaneada de una captura de pantalla impresa del programa NoteCards. Licencia CC BY 2.0.
Imagen escaneada de una captura de pantalla impresa del programa NoteCards. Licencia CC BY 2.0.
Bien parece que durante la década de 1990 no hubo demasiadas novedades en este ámbito, porque no pude encontrar lanzamientos de programas administradores de notas que hayan tenido un impacto registrado. Lo que se encuentra a continuación es el lanzamiento de Microsoft OneNote, como un producto no incluido en su suite ofimática Office en 2003 y, por tanto, de compra separada. Este programa tuvo cierto impacto en los usuarios de aquel entonces, porque suele reseñarse de manera muy positiva y como una innovación no vista antes. Un usuario narra, en retrospectiva, sus primeras impresiones ante el arribo de este programa en 2003:
As I told OneNote lead designer Chris Pratley at COMDEX that year, it felt like Microsoft had made this new application just for me: Then, as now, I spent a lot of time meeting with people from Microsoft and other companies, recording their words in written form, and I would use those quotes for the basis of later articles. OneNote might have seemed superfluous to some, especially at that time, since one could simply use Word for that purpose. But I saw the genius and utility behind a tool that could be used purely for capturing and organizing the notes that would later be used—yes, in Word—to create formal articles. And I was eager to begin using it.
Se observa un programa diseñado para lidiar con borradores, a diferencia de Microsoft Word, los cuales pueden organizarse en forma de "archivadores", con pestañas, adjuntar documentos, incorporar hiperenlaces y compartir anotaciones con otros programas de Office, como Outlook y el capturador de pantalla del sistema. Sin embargo, el impacto de este programa sería opacado por otro, al terminar esa misma década, surgiendo una competencia muy fuerte, que además de presentar esas opciones, estaba directamente enfocado en la sincronización en línea y la interoperatividad con dispositivos móviles. De la mano del desarrollador ruso, Stepan Pachikov, hacemos referencia al programa EverNote, que luego de lanzado en 2008 no dejaba de ganar usuarios nuevos. Al presentarse como una aplicación sencilla, con una interfaz atractiva y que permitía labores complejas en la creación, organización y difusión de notas, EverNote tuvo un éxito sin precedentes entre los usuarios, el cual, lamentablemente, no supo mantener, al intentar diversificar su oferta, incorporando funciones que presentaban problemas técnicos y cambiando sus políticas de privacidad de un modo que preocupaba a sus propios usuarios. Debe tomarse en cuenta, además, que en los inicios de la década de 2010, Microsoft, fiel a su estilo, modificó OneNote, primero, en 2007, incorporándolo a su suite ofimática Office, luego, en 2012, sorprendentemente, lanzando su versión para Android, lo que le permitió competir con EverNote. Por otro lado, por este mismo periodo, aparecía Google Docs, luego convertida en la suite ofimática de Google, mediante Google Drive, la que inicialmente representó una fuerte competencia para EverNote, al ser un servicio de almacenamiento sincronizado de archivos en línea, con capacidades de lectura y edición compartida, introduciendo, además de esto, en 2014, Google Keep, un editor de notas simple y atractivo, si bien, con funciones más básicas que los anteriores.
Sin embargo, ya habiéndose diversificado la oferta de programas, con todo tipo de funciones, incluida la sincronización, como se mencionó, el programa que probablemente cambiaría las reglas del juego en este nicho, por las innovaciones introducidas, es Notion, que a mediados de la década de 2010, lanzaba su ambiciosa propuesta, fuertemente imbuida en el concepto de hipertexto y que actualmente, genera bastante impacto entre los usuarios, sobre todo, pertenecientes al sector de gestión empresarial. Notion lleva la idea de tomar notas a otro extremo, añadiendo nuevas funcionalidades, por ejemplo, hipervínculos entre notas y, los llamados "bloques", que permiten incrustar diversas funcionalidades a la nota, desde títulos, etiquetas, imágenes, casillas de verificación, tablas, etc., los cuales además, indexan los apuntes. Una vez lanzada esta idea, no faltó la competencia mejorada y, a finales de la década de 2010, surge Obsidian, que si bien, sigue la misma premisa de Notion, rinde un homenaje más extremo a la idea de hipertexto, permitiendo visualizar, mediante un gráfico de hipervínculos, las relaciones entre todos los apuntes generados en su entorno.
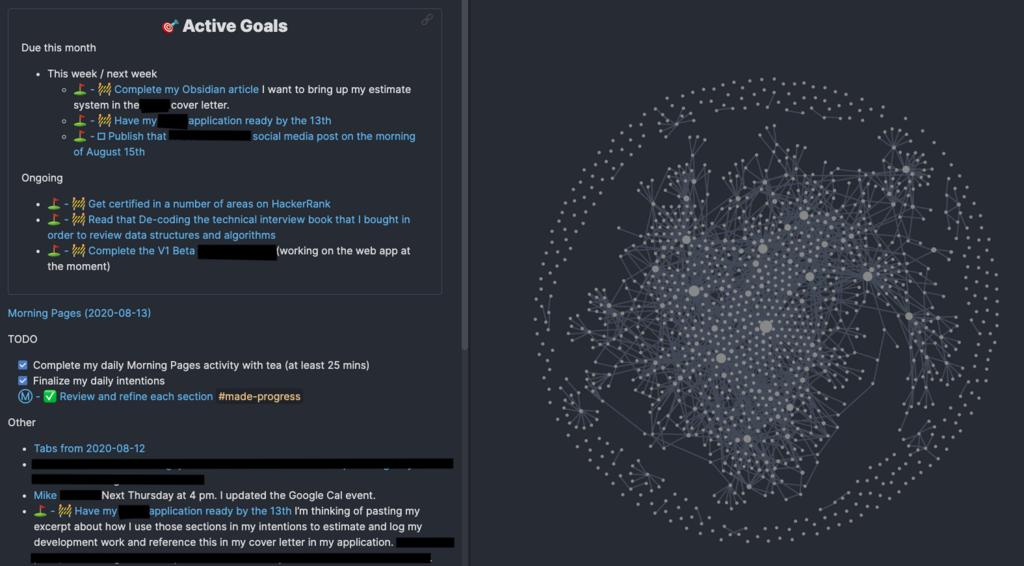 Captura de pantalla de la intefaz de Obsidian, con su famosa vista previa de los hipervínculos
Captura de pantalla de la intefaz de Obsidian, con su famosa vista previa de los hipervínculos
Afrontando el desafío: mi experiencia personal
De los procedimientos anteriormente descritos, en los cuales se usa el hipertexto, ya sea de forma digital o analógica, se puede crear una división de tres usos: el uso académico, el productivo y el literario. A partir de ahora, me concetraré solo en el uso académico y productivo, tomando en cuenta, sobre todo, que yo no soy un escritor de ficción, aunque, algunas ideas surgidas de este campo serán de utilidad para este escrito, como se apreciará posteriormente.
Es interesante constatar que la vida cotidiana de una persona no necesariamente se divide, tan claramente, entre las esferas académica y productiva, es decir y, por ejemplo, el esfuerzo académico de alguien, en alguna materia del conocimiento, puede estar también dirigido a modificar la realidad, teniéndose en cuenta que todo buen proyecto es precedido de un profuso diagnóstico y, una vez implementado, sus resultados pueden crear aportes, no solo a sus propios objetivos, sino a los principios científicos en los que se basó su ejecución. Quiero citar aquí el ejemplo de los famosísimos hermanos Wright, los considerados pioneros de la aviación, cuya actividad económica, previa a sus logros aeronáuticos, era la fabricación y reparación de bicicletas, actividad productiva que no solo les proporcionó esforzadas ganancias económicas, sino también destrezas técnicas, que les permitió dar su posterior y sorprendente salto a la gloria, no solo económica, sino también científica. A las personas que los conocían, les costó años, literalmente, superar la negación de que esos "bicicleteros" habían triunfado en algo que las mentes científicas más prodigiosas de la época no lo habían hecho. Sin embargo, más allá de este bonito ejemplo, puede darse el caso de que la actividad académica o científica de un individuo sea también su actividad productiva, sobre todo, si se habla de profesores universitarios, consultores, difusores, etc. y; a la inversa, a un ejecutivo del sector productivo, si bien, le interesará aplicar las más recientes innovaciones científicas a su labor, sus mayores esfuerzos no estarán dirigidos a crear conexiones entre fuentes bibliográficas o, experimentos científicos, sino, a la gestión de recursos con el fin de obtener ganancias.
Academia
En mi caso, mi actividad académica se limita a la realización de investigaciones y escritura de ensayos en el área de ciencias sociales e historia, en el marco de mis estudios para obtener algún grado académico. En este aspecto, mis técnicas de estudio son, podría decirse, bastante convencionales, a tal punto que quedé gratamente sorprendido con los métodos de elaboración de fichas bibliográficas, basados en la idea de hipertexto, que recién conocí mientras investigaba documentos para la elaboración de este escrito, sobre todo, la técnica alemana zettelkasten. Quiero ser más detallado. Mi proceso de elaboración de una investigación se limita a crear reseñas bibliográficas de cada documento que consulto, en documentos de texto almacenados en el ordenador; luego, cuando creo que ya agoté la bibliografía del tema, descompongo esos resúmenes, clasificándolos en temas y subtemas; después, creo un nuevo texto, esta vez, organizado sobre la base de los temas abordados, declarando las relaciones entre documentos, ya sean, contradictorias o convergentes y, en este último caso, es también importante identificar las sensibles diferencias, a pesar de una coincidencia genérica; finalmente, para hacer las conclusiones, primero, me hago un mapa mental que descomponga todas las ramificaciones y relaciones del problema, que hallé con el ejercicio anterior, luego, elaboro una narración de mis hallazgos, para también aportar mis propias percepciones, con el objeto crear conocimiento nuevo respecto al tema.
Para este último proceso, el de las conclusiones, uso el fabuloso programa de código abierto Freeplane, que está hecho simplemente para crear mapas mentales. Yo sé que existen muchos programas de este tipo, los hay más nuevos y con una interfaz más moderna y atractiva, incluso para usarlos en línea, pero este, está muy bien pensado y tiene una plétora de opciones que otros no. Hay que tomar en cuenta que tiene una historia de más de una década de desarrollo.
Regresando al tema, es interesante comparar mi proceso de estudio con la técnica zettelkasten. Si bien, no hay una sola forma de usar la técnica zettelkasten, revisando sus procedimientos comunes me voy dando cuenta de cómo podrían beneficiar a mi actual forma de manejo de conocimiento. Por ejemplo, como expuse, yo resumo y comento mis documentos, en ocasiones los "traduzco" en un lenguaje más comprensible y apunto mis percepciones, luego, junto todo y lo "descompongo" con base en temas, buscando sus relaciones. En la técnica zettelkasten, a diferencia de mi procedimiento, a medida que se toman apuntes ya se los va ordenando inmediatamente, primero, de forma jerárquica, de acuerdo a su tema o subtema, juntando las notas con sus pares y, luego, se le pueden añadir metadatos, es decir, etiquetas de todo tipo que el investigador encuentre pertinente, los cuales permitirán encontrar relaciones con notas, localizadas posiblemente en una zona temática extrema. De esta forma, el autor puede visualizar instantáneamente las relaciones entre sus notas, obteniendo un hipertexto en todo su esplendor 🤩.
Hay un segundo aporte que encuentro útil en la técnica zettelkasten y, es que, el procedimiento que yo narro, lo ejecuto en cada investigación que hago, sin embargo, al ser la técnica zettelkasten, una práctica que se la usa perfectamente para el manejo de un archivo, sin importar su envergadura, podría servirme en mi caso para juntar todos mis apuntes realizados hasta la fecha y, crear un hipertexto de toda mi producción, es decir, una auténtica organización de fichas bibliográficas. Es importante mencionar aquí que esto es justamente lo que practicaba el gran sociólogo Niklas Luhmann, quien construyó un zettelkasten de alrededor de 90.000 fichas, sobre la base del cual desarrolló su prodigiosa teoría de sistemas, la cual, trasciende el ámbito de la aplicación de la sociología, al proponer, de forma muy ambiciosa, el concepto de sistema, es decir, la interdependencia de las partes que conforman un todo, como forma de comprender todas las áreas de conocimiento. El zettelkasten de Niklas Luhmann fue puesto a disposición del público de forma digitalizada.
Aquí ya podría comenzar a reflexionar respecto a qué software puedo utilizar para crear mi propio zettelkasten, pero prefiero dejar este tema para después, porque considero que puedo abordarlo luego de describir la organización de mi proceso productivo.
Productividad
Creo que las técnicas de manejo de productividad actualmente están representadas por la escritura y organización de apuntes personales; creación de recordatorios; clasificación de tareas, como se vio, ya sea basándose en su prioridad, contexto o proyectos personales; seguimiento de la planificación; manejo de agenda según calendario; etc. Sin ánimo de ser exhaustivo y, tomando en cuenta la diversidad de enfoques que existen, me parece que, ya en términos de programas de uso sincronizado entre el ordenador y los dispositivos móviles, estas funciones pueden dividirse en: libreta de apuntes; administrador de tareas, vía casillas de verificación y; calendario con funciones de agenda electrónica. Es cierto que estos desempeños, dependiendo de la técnica de organización seguida o, el programa revisado, pueden integrarse en un solo espacio o, sus prestaciones estar entremezcladas. Por ejemplo, los programas de tareas suelen venir con su propia ejecución de calendario, sin que el programa sea una aplicación de agenda, con todas las funciones que esto implica; en otras ocasiones, esta función está integrada en un programa de calendario, cuyo rol se diferencia claramente de los eventos, que se los entiende, necesariamente, como una actividad con fecha de ejecución, que puede, a su vez, agrupar tareas e incluir a más de una persona. Y, al contrario, una de esas funciones puede subdividirse más, por ejemplo, los clásicos apuntes, que son simplemente texto, pueden adquirir especializaciones como, recopilación de páginas web en forma de marcadores o hipervínculos; las propias listas de tareas, mediante casillas de verificación, que pueden surgir de los apuntes; la creación de tablas, para hacer seguimientos de todo tipo, sobre la base de varios criterios de verificación; etc.
En este ámbito productivo soy, incluso, mucho menos prolijo que en el académico. Desde que estaba en secundaria se me enseñó a manejar una agenda para organizarme, sin embargo, nunca demostré mucha predisposición a ser sistemático con mis labores, había momentos en los que usaba la agenda de forma detallada, pero, luego la olvidaba, me distraía con facilidad. Cuando estaba en la universidad, manejaba Windows 7, elaboraba notas rudimentarias en Microsoft Word, a modo de guardar recordatorios o enlaces de páginas web, luego, descubrí el widget que simulaba las sticky notes en la pantalla y, los documentos de texto creados con el bloc de notas. En el dispositivo móvil, sucumbí tempranamente a EverNote, desde mi BlackBerry, donde hacía lo mismo que mencioné anteriormente, luego, no recuerdo bien por qué, me pasé a Google Keep, donde comencé a manejar listas de compras por este medio, ya que permitía manejar casillas de verificación. Fue cuando me pasé a Linux que realmente profundicé en este tema, ya que el catálogo de programas que ofrece una distribución Linux, permite observar una gran cantidad de opciones en este sentido.
Ya en ese sistema, comencé a familiarizarme con el método Getting Things Done, el cual no conocía antes y, descubrí gracias a un programa de Linux muy llamativo, denominado Getting Things GNOME (la variación del nombre se debe a que está diseñado para ser compatible con el escritorio GNOME, para Linux). En un principio, esta aplicación aparenta ser un simple administrador de casillas de verificación de tareas, sin embargo, lo que me sorprendió fue que esas casillas podían subdividirse a su vez en otras casillas de verificación o subtareas, de forma ilimitada; además de eso, podían relacionarse tareas de cualquier rama jerárquica de las actividades, creando hipervínculos entre sí: a esto se llama hipertexto. Aquello me permitió concluir algo muy importante: que todas las actividades de la vida de una persona o, incluso de una organización, pueden expresarse en una lista de tareas, no importa cuan ilimitada termine siendo esta al final y, ante esa cantidad, estas deben organizarse de acuerdo a los métodos revisados anteriormente. Al tener correctamente jerarquizadas todas esas tareas, se obtiene una especie de "mapa" al que uno puede volver cada vez que se encuentra saturado y olvida sus prioridades, obteniendo así la información clara que le permita decidir qué hacer, en orden de obtener los resultados buscados.
Sin embargo, dos cosas me obligaron a buscar otros programas para continuar con semejante labor: primero, a los desarrolladores de Getting Things GNOME no les interesa mejorar sus mecanismos de sincronización con otros dispositivos, algo que actualmente es muy importante (si bien, tienen esta opción, se mantiene hace demasiado tiempo en una fase experimental); segundo, hace más de dos años que no se compila una nueva versión, lo cual es inaceptable, tomando en cuenta los cambios, la seguridad y la competencia. Tengo entendido que es un proyecto iniciado en 2009, que fue rescatado en 2020, ante un abandono de años, por el desarrollador Jean-François Fortin Tam. Al parecer, nuevamente atraviesan por dificultades similares. Ante estos inconvenientes, en esos entonces, no encontraba entre los programas de Linux y, con esto me refiero no solo a los vastos repositorios de una distribución como Debian, sino también a Flathub, una aplicación de programación de tareas que tenga la funcionalidad de anidar subtareas en una tarea, de forma ilimitada y, que, además, sincronice decentemente entre dispositivos. En realidad, sí existían algunas aplicaciones, pero, lamentablemente, no cumplían otros requerimientos de elegibilidad que yo exijo a los programas e, incluso, a mi sistema operativo. Inicio un paréntesis.
Trato, en lo posible y, aquí pongo un énfasis porque claramente a veces no lo es, de utilizar software de código abierto, por los motivos que expongo en la primera entrada de este blog, que básicamente se resumen en: confianza, seguridad y estabilidad. Solamente hago excepciones en casos de emergencia, las cuales suelen ser usualmente laborales. Por ejemplo, me veo en la imperiosa necesidad de utilizar la aplicación de mensajería Whatsapp y usar un dispositivo Android, debido a esto, precisamente. Luego, es muy importante para mí que el programa tenga buenas opciones de exportación y respaldo de mis datos, para que, en caso de que ese programa deje de existir, pueda exportar mi información a otro programa sin ningún perjuicio. En ese sentido, si bien, me interesan las opciones de sincronización, esta debe funcionar necesariamente sobre mi almacenamiento local, para que incluso pueda trabajar sin conexión, de ser necesario. Un programa que, además de, solo trabajar en "la nube" y, que además sea privativo o, de forma más correcta, software como servicio, levanta demasiadas banderas rojas para mí. Finalmente, prefiero programas con estabilidad comprobada y que usen Wayland por defecto, entre otras características que no vale tomar en cuenta aquí, porque son de menor importancia y, además no es bueno seguir perdiendo el foco del tema.
Regresando al asunto, estaba buscando un software de uso personal que simplemente me permita manejar casillas de verificación, esto no es algo demasiado complejo y, si bien, Google ofrece un buen programa en ese sentido, llamado Tasks y, como ya de todas formas uso los servicios de Google por necesidad, estaba dispuesto a probarlo, pero, en esos entonces no había un cliente decente en Linux (ahora ya lo hay). Las opciones privativas en Linux eran Todoist y TickTick, pero, como esto no era una emergencia, prescindí de su descarga. Un excelente servicio de código abierto basado en la sincronización en la nube es Nextcloud notes, pero, por algún motivo, igualmente, no había un cliente decente en Linux, que no sea el propio navegador. Todo apuntaba a que iba a terminar acercándome al manejo analógico de una lista de tareas, pero sin necesidad de recurrir al papel, sino mediante un administrador de notas que funcione con Markdown. Lo bueno es que esto no fue necesario, porque luego de investigar bien encontré una solución genial que me fascinó, ya que, no solo se acercaba bastante a la solución que yo buscaba, en texto plano, sino que, sorprendentemente, sobre esa base, incluso tenía funciones tan complejas como las de Getting Things GNOME. Pero, primero quiero exponer mis experimentos previos con Markdown, cuando pensaba manejar mis tareas desde un archivo de texto, con el fin de demostrar que esto no es complicado y, además, es interesante.
Markdown es un formato de texto cuyo objetivo es, primero, otorgar características de marcado (tamaño, itálicas, subrayado, tablas, etc.) y; segundo, que pueda ser leído fácilmente por humanos 😳. Los formatos de texto enriquecido, como tienen características de estilo que van más allá de los caracteres, que en sí ya son unidades de información por sí mismos (en este caso el alfabeto), necesitan anexar más símbolos a ese texto base, para indicar esas cualidades de forma. Si se mantuvieran en formato plano producirían distorsiones en su lectura, por ello, un programa que renderiza estos símbolos los formatea adecuadamente. Entonces, Markdown se propone, no solo formatear el texto, sino que aunque este no esté renderizado sea de fácil lectura.
A continuación se muestra un texto formateado con Markdown, el cual puede editarse y leerse con cualquier editor de texto, como el Blog de notas de Microsoft, por ejemplo:
## Título
### Subtítulo
Este es un ejemplo de texto que da entrada a una lista genérica de elementos:
- Elemento 1
- Elemento 2
- Elemento 3
Este es un ejemplo de texto que da entrada a una lista numerada:
1. Elemento 1
2. Elemento 2
3. Elemento 3
Al texto en Markdown puedes añadirle formato como **negrita** o *cursiva* de una manera muy sencilla.
Ahora, uno con HTML, que es el formato utilizado para crear páginas web, donde se puede apreciar, cuál es más complicado de realizar y leer:
</head>
<body>
<h2 id="título">Título</h2>
<h3 id="subtítulo">Subtítulo</h3>
<p>Este es un ejemplo de texto que da entrada a una lista genérica de elementos:</p>
<ul>
<li>Elemento 1</li>
<li>Elemento 2</li>
<li>Elemento 3 Este es un ejemplo de texto que da entrada a una lista numerada:</li>
</ul>
<ol type="1">
<li>Elemento 1</li>
<li>Elemento 2</li>
<li>Elemento 3 Al texto en Markdown puedes añadirle formato como <strong>negrita</strong> o <em>cursiva</em> de una manera muy sencilla.</li>
</ol>
</body>
</html>
De hecho, el programa que crea este sitio web, me pide que escriba esta entrada en formato Markdown y, para renderizar la página en el servidor, convierte el texto al formato HTML. El caso es que hay unos fabulosos administradores de notas personales diseñados para que esas notas sean tomadas en formato Markdown y, de ser necesario, visualizadas instantáneamente, soportando un sistema de casillas de verificación. A continuación presento un ejemplo ficticio, en formato Markdown:
**Lista de actividades 2025**
- [ ] Establecer un nuevo récord Guinness por el libro con más rechazos en editoriales del mundo:
- [ ] Investigar editoriales:
- [x] Buscar editoriales conservadoras
- [ ] Crear una base de datos
- [ ] Hacer trabajo de campo para afinar resultados
- [ ] Escribir el libro:
- [ ] Investigar temas polémicos
- [ ] Buscar en redes sociales
- [x] Preguntar a ChatGPT
- [ ] Revisar bibliografía
- [ ] Crear el borrador
- [ ] Realizar retroalimentación con editores reales
- [ ] Registrar los rechazos:
- [ ] Investigar sistemas de verificación
- [ ] Implementar el sistema
- [ ] Postular a los record Guiness
- [ ] Trabajo como ministro de educación:
- [ ] Planificación del año escolar:
- [x] Exigir a los viceministros que hagan el plan
- [ ] Procesar el plan con ChatGPT
- [ ] Enviarles las observaciones y correcciones
- [ ] Coordinación:
- [ ] Asistir al 20% de las reuniones
- [x] Delegar a los viceministros
Dicha lista se renderizaría de la siguiente manera, mediante programa:
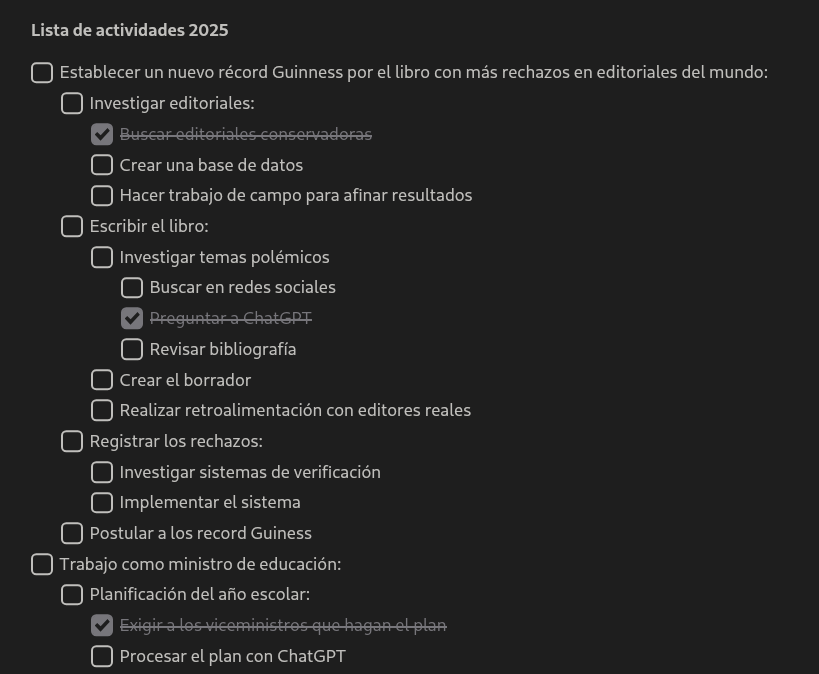 Captura de pantalla del programa Iotas para Linux
Captura de pantalla del programa Iotas para Linux
Ahora, esto no está mal, porque tanto en el móvil como el ordenador hay programas que manejan notas personales que procesarían sin problema esa lista: me refiero a Nextcloud Notes, en el teléfono e; Iotas en el ordenador. Actualmente, esos son mis programas predeterminados para tomar notas, sin embargo, ya no los uso para administrar mis tareas, ya que, como mencioné, encontré otro formato de texto, así como Markdown, pero especializado en tareas y, si bien, se lo puede usar sin un programa visualizador, es decir, guardando las tareas en un archivo de texto, es soportado por varios programas y puede asumir una complejidad como la del ejemplo.
Todo.txt, es un proyecto que creó ese formato y un programa que lo gestiona desde la terminal. A mí me parece genial porque además de todo, se propone conciliar el método Getting Things Done con el método Einsenhower, es decir, la gestión de tiempo, ya sea, desde proyectos y contextos o desde prioridades. El formato es el siguiente y, aclaro, nuevamente, que se puede abrir con cualquier editor de texto:
Referencias:| Componente | Función |
|---|---|
| x | Señal de completado |
| (A) | Clasificación de prioridad |
| Primera fecha | Fecha de completado |
| Segunda fecha | Fecha de creación |
| Frase | Descripción de la tarea |
| + | Etiqueta de proyecto |
| @ | Etiqueta de contexto |
| due | Plazo de finalización |
Si transformamos la anterior lista de tareas a este formato, se vería así:
x 2024-12-01 2025-01-20 Buscar editoriales conservadoras +Guiness +Editorial @Personal
(B) 2024-12-01 Crear una base de datos +Guiness +Editorial @Personal
(A) 2024-12-01 Hacer trabajo de campo +Guiness +Editorial @Personal
(A) 2024-12-01 Buscar temas polémicos +Guiness +Escritura @Personal due:2025-02-03
(A) 2024-12-01 Buscar en redes sociales +Guiness +Escritura @Personal
x 2024-12-01 2025-01-20 Preguntar a ChatGPT +Guiness +Escritura @Personal
(A) 2024-12-01 Revisar bibliografía +Guiness +Escritura @Personal due:2025-02-28
(B) 2024-12-01 Crear el borrador +Guiness +Escritura @Personal
(B) 2024-12-01 Realizar retroalimentación con editores reales +Guiness +Escritura @Personal
(A) 2024-12-01 Investigar sistemas de verificación +Guiness +Registro @Personal
(B) 2024-12-01 Implementar sistema de verificación +Guiness +Registro @Personal
(B) 2024-12-01 Presentar verificaciones +Guiness +Postulación @Personal
x 2024-12-01 2025-01-20 Exigir a los viceministros que hagan el plan +Planificación @Trabajo
(C) 2024-12-01 Procesar el plan con ChatGPT +Planificación @Trabajo
(C) 2024-12-01 Enviar observaciones y correcciones +Planificación @Trabajo
(C) 2024-12-01 Asistir al 20% de las reuniones +Coordinación @Trabajo
(D) 2024-12-01 Delegar a los viceministros +Coordinación @Trabajo
Nótese, luego de una revisión detallada, que esa pequeña maraña de tareas y subtareas ahora se ve eficientemente clasificada, incluso sin la necesidad de renderizado de un programa. Tranquilamente, se podría manejar un archivo de texto de esa forma y ya, sin embargo, si se usa un programa para administrar ese archivo, la potencia del formato es evidente, ya que se pueden crear filtros y ordenamientos personalizados. Esta sería la vista desde el programa Sleek para Linux:
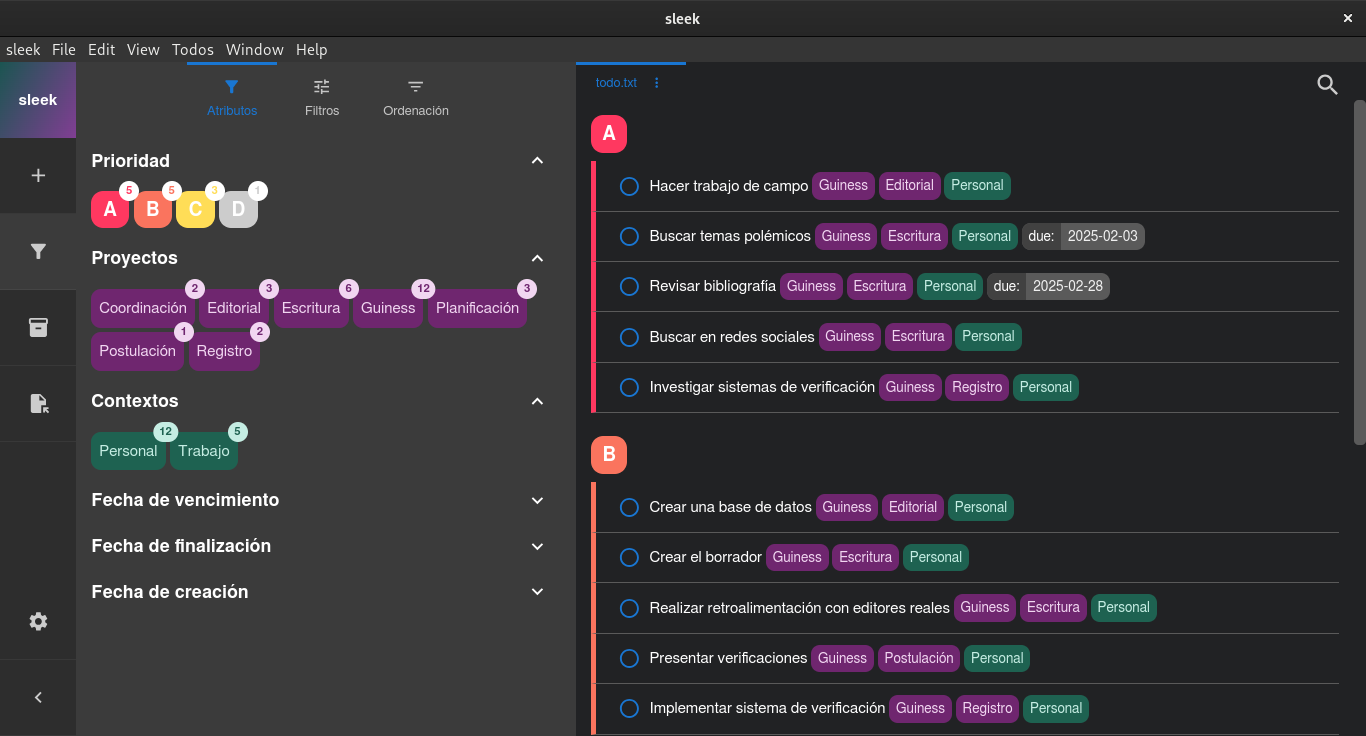
Durante alrededor de dos años, utilicé ese formato para organizar mis tareas, mediante el ya nombrado programa Sleek, para un ordenador con Linux, además de la fabulosa extensión para el escritorio GNOME y; para el móvil, Simpletask, mediante un archivo sincronizado por NextCloud. Pero, lamentablemente, dejé de usar ese formato, debido a que el desarrollador de Simpletask decidió abandonar su proyecto y, si bien, apareció otra aplicación para Android denominada ntodonxt, cuando la probé tenía serios problemas con la sincronización de Nextcloud (no sé si a la fecha esto se habrá resuelto). Por suerte, apareció el programa Errands (en español, Recados), que ahora tiene una excelente compatibilidad con la aplicación nativa para manejo de tareas de Nextcloud, mediante la extensión del protocolo HTTP, WebDAV, bajo el estándar CalDAV, que también tiene compatibilidad con Google Tasks y Todoist. Esto, en el caso del ordenador, bajo el sistema operativo Linux. Para Android, encontré la fabulosa aplicación Tasks, compatible con la sincronización de Nextcloud. Además de esto, mi administrador de correo electrónico, Mozilla Thunderbird, es compatible con este formato. Finalmente, el estándar CalDAV, al igual que Todo.txt, es plenamente compatible, tanto con el método Einsenhower como con Getting Things Done.
Finalmente, el software que utilizo para mi "productividad personal" es el siguiente:
| Función | Linux | Android |
|---|---|---|
| Notas | Iotas | Nextcloud notes, Quillpad |
| Tareas | Errands | Tasks |
| Calendario | Mozilla Thunderbird; GNOME Calendar | Google Calendar |
El efecto Notion
Como mencioné al inicio de esta entrada y, de acuerdo a lo que descubrí mientras investigaba para escribir estas líneas, si bien, Notion está transformando la oferta de aplicaciones para escribir y organizar notas personales, profundizando el concepto de hipertexto, esta idea en realidad no es novedosa y se llevó a cabo ya en la década de 1980, a través del programa NoteCards. En este apartado quiero identificar correctamente la manera en la que estos cambios pueden afectar de forma positiva la ofimática de las personas, luego, de forma negativa y, finalmente, cómo estoy encarando estas novedades en mi vida personal.
La idea
De acuerdo a lo que se expuso en el apartado de programas para tomar notas, es decir, de manera digital, la propuesta de Notion se basa en: diversificar la forma en que se toma apuntes, a partir de la introducción de más funciones automatizadas; luego, profundizar en la interrelación de esos textos, manejándolos como un auténtico hipertexto o, si se quiere, una wiki, no necesariamente comunitaria, si se permite este abuso semántico con el propósito de hacer comprensible el concepto (por definición, toda wiki es colaborativa) y; finalmente, la creación de un entorno cerrado, cuasi autosuficiente, que rivaliza, incluso, con el sistema operativo. Profundicemos en esto último: un sistema operativo es más que un conjunto de programas, es también una base de servicios que permite a los programas interactuar con el hardware; en ese sentido, si bien, Notion, está lejos de considerarse un sistema operativo, su idea de prescindir, en lo posible, de programas externos a su entorno, podría derivar en el largo plazo en la propuesta de un sistema operativo propio o, incluso, en una influencia de este enfoque en los sistemas operativos tradicionales, como Windows, Linux y macOS. Notion y programas similares, podrían estar apuntando a convertirse en un nuevo sistema operativo, mientas que los sistemas operativos tradicionales, en respuesta, podrían adoptar las ideas de interdependencia de funciones, de Notion, desde el administrador de archivos, neutralizando así estas ambiciones.
El impacto positivo de esta tendencia podría ser, eso justamente, es decir, que a un segmento importante de la población le beneficiaría esta profundización de la función de hipertexto en el sistema operativo; sin embargo, el aspecto negativo sería el aprovechamiento inescrupuloso de las compañías detrás de estas ideas, a partir de la creación de una excesiva dependencia de los usuarios a su entorno cerrado, privativo y automátizado. Esto último, ya es llevado a cabo de manera similar por el denominado "ecosistema" Apple, que pone trabas a la interacción e interoperatividad con hardware y software de otras compañías.
En lo que a mí respecta...
De acuerdo a lo que expuse en la sección de programas de mi uso personal, no hay forma de que adopte Notion, de forma voluntaria en mi vida diaria, debido principalmente a que no tiene una licencia de código abierto; además, no trabaja sobre la base de una copia local de los datos personales y el trabajo sin conexión es limitado; por último, hay serias dudas de la comunidad respecto al manejo transparente de datos personales por parte de la compañía. Hay buenos ejemplos respecto a esto: hace unos años, una influencer, de nombre Harshibar, que construyó su éxito en redes sociales a partir de consejos de productividad, basados principalemente en Notion, publicó un video en el que, de forma sorpresiva, se mostraba preocupada respecto a la seguridad de sus datos personales almacenados por Notion, ya que el servicio no ofrecía cifrado de extremo a extremo y; es lamentable constatar que, a pesar de esos reclamos, la situación continúa siendo la misma actualmente. Además, Notion no tiene un cliente oficial para Linux.
La competencia de Notion, realiza una mejor labor en este sentido, por ejemplo, Obsidian, permite trabajar con una copia local de los datos personales y, además, ofrece cifrado de extremo a extremo; el problema, en mi caso, es que Obsidian no está construido bajo una licencia de código abierto, aunque tiene un excelente cliente oficial para Linux. Afortunadamente, existe una aplicación, competencia de Notion, que suele calificarse como una aproximación intermedia, precisamente entre Notion y Obsidian, que no solo es de código abierto, sino que permite trabajar sobre copias locales de los datos personales, ofrece cifrado de extremo a extremo y tiene dos excelentes clientes para Linux: hago referencia a Anytype.
Hace unos días ejecuté la versión AppImage de Anytype para Linux, con la intención de probar y, siendo sincero, me resultó un poco "asfixiante", claramente tiene su curva de aprendizaje. Esta nueva forma de programa "navaja suiza" de notas, tiene demasiadas opciones que así, de forma intuitiva, cuesta decidir para qué utilizar. Y, ciertamente, no soy la única persona que piensa o se siente así: en el siguiente video, el influencer de productividad, Matthew Gira, explica las razonas por las que considera que Notion no es una herramienta para todas las personas, especialmente, para aquellas que tienen escasas habilidades digitales, recomendando programas más amigables y directos para estos casos; lo mismo sucede en este podcast, para usuarios de Linux, en el que los participantes argumentan que Obsidian les resultó abrumador y sugieren herramientas menos complejas para manejar sus notas personales.
Tomando en cuenta todas estas cuestiones, sin embargo, todavía no me cierro 100% a la ídea de usar Anytype, aunque primero, quiero explorar otras posibilidades. Antes de tener la oportunidad de probar Anytype, investigué Notion y Obsidian y me percaté que sus funciones no eran tan trascendentales en mi día a día y que, en caso de necesitarlas, podía emularlas, de forma similar, con herramientas ya existentes en mi sistema operativo. Primero, si alguien usa estos programas de "gestión del conocimiento", para lograr organizar sus archivos personales de forma significativa y consistente a sus proyectos, los sistemas de organización de archivos del ordenador existen desde antes de surgir estos programas. Hay dos videos muy interesantes respecto a esto, hechos por influencers a los que yo mismo sigo en mi día a día: el primero, de Lea David, muestra, desde un ordenador con Microsoft Windows, la forma en la que ella organiza sus archivos personales y laborales; luego, Jeff Su, expone su propio sistema, pero desde Google Drive. Personalmente, no sigo al pie de la letra estas recomendaciones, sobre todo en lo relacionado con el nombramiento de archivos, con fecha de creación o modificación, porque, esos metadatos ya están grabados en los archivos por el sistema, de forma automática, considero, por tanto, que esto es hacer doble esfuerzo y, el buscador de los escritorios Linux es lo suficientemente potente para encontrar esa información cuando se la solicita. Por otro lado, lo que me parece esencial en estas recomendaciones es que la organización de las carpetas y archivos mantenga una correspondencia con la lista de tareas personales, sobre todo, con los contextos y proyectos, para no perder la vista general de todos esos propósitos.
Segundo y, sin embargo, algo que se perdería aquí, incluso a pesar de la buena organización de los archivos, es la idea de hipertexto. Recordemos que el hipertexto está representado por la interrelación de las partes con el todo, lo que genera un sentimiento de casi omnipresencia, de control, de cada aspecto de nuestra producción. Las aplicaciones tipo Notion, proporcionan esa experiencia de un modo más intenso que el descrito anteriormente. Por ejemplo, en la página de inicio de mi libreta de anotaciones podría estar mi lista de labores personales, clasificadas por tareas y subtareas, contextos y proyectos y, jerarquizadas por prioridades. Lo que este tipo de programas permite hacer, siguiendo el ejemplo, es convertir cada eslabón de ese esquema, en este caso, la representación de las actividades, no solo en un simbolismo de mis objetivos, sino, literalmente, en un enlace a las actividades que dan forma a esa labor. Al dar clic en cada una de esas ramas, el programa reunirá a todos los archivos del ordenador (notas, tablas, archivos de imágenes, planificación de la agenda, etc.) que estén vinculados a ese propósito.
Cuando fui consciente de eso, me pregunté, seriamente, hasta qué punto necesitaba que todos los archivos de mi ordenador formen parte de un hipertexto. Es decir, entiendo la idea y sospecho que a varias personas esto les es útil. Me imagino el ejemplo del gerente comercial de una gran empresa, cuyas labores deben señirse, "milimétricamente", al detallado plan de acción establecido desde los mandos superiores. En ese caso, parece una muy buena idea convertir todos los archivos del ordenador en un hipertexto, armado además, alrededor de un esquema central, para que ninguna acción personal se desvíe de la meta, a causa de una distorsión de la focalización, tomando en cuenta el flujo de información, no solo laboral, sino, personal, que transita por los dispositivos de esa persona. Si bien, en mi caso, me hallé en situaciones en las que mi flujo de actividades aumentaba en cantidad y dificultad, esto sucedió solo por momentos y, superé tales obstáculos sin necesariamente convertir mis archivos personales en un hipertexto.
Volviendo a la idea, si la organización de archivos personales es todavía confusa, el administrador de archivos del sistema, algunos editores de texto simple y, todos los procesadores de texto enriquecido, permitirían resolver este problema. Una opción es crear accesos directos a archivos prioritarios del sistema, en la carpeta personal o subcarpetas principales. El administrador de archivos Nautilius, en Linux, permite asignar una seña a archivos y carpetas que el usuario considere importantes para que se presenten en una sección permanente del programa. Por otro lado, si realmente se considera necesario vincular varios archivos a un esquema general o parcial, de las actividades del usuario, se puede crear un archivo de texto, como se mencionó, ya sea simple o enriquecido, al que se le agreguen hiperenlaces dirigidos a otros archivos. Por ejemplo, tanto Microsoft Word y LibreOffice Writer permiten hacer eso con sus archivos de texto. Luego, editores de texto, como Apostrhophe, que además, están enfocados en Markdown, también permiten crear archivos con hipervínculos a archivos externos, que fungirían como índices o mapas generales dentro las carpetas de proyectos. Esta última opción es la que yo personalmente usaría para diferenciar estos archivos, con propósitos de indexación, del resto de archivos, con extensiones más comúnmente usadas en el día a día.
Finalmente, explorando programas que toman notas en formato Markdown en Linux, descubrí uno que me llamó poderosamente la atención: se llama Zetrlr y, además de permitir tomar apuntes de una forma tradicional, tiene la opción de convertir esos apuntes en un zettelkasten, literalmente. El programa tiene una función llamada zettelkasten, mediante la cual se añaden metadatos a las notas, que a su vez, son hipervínculos que ordenan y jerarquizan los textos. Este programa, me parece que fuera un intermedio entre los programas para tomar notas que uso actualmente y, programas tipo Notion, como Anytype, en el entendido de que si bien, permite convertir las notas en un hipertexto, lo hace de una forma menos compleja de aprender.
Al momento que estoy escribiendo esta entrada no exploré en profundidad y, de forma sostenida, Anytype o Zetrlr; probablemente, cuando tenga tiempo lo haga y, a pesar de todas esas consideraciones anteriores, no me cierro a la posibilidad de terminar adoptando alguno. Me llama la atención, la posible creación de un hipertexto que "una" mis proyectos personales con los laborales, o mi ámbito productivo con el académico y, verificar si puedo encontrar relaciones útiles entre todos esos aspectos de mi vida.
Para finalizar, volvamos a la ficción 🧙♂️
Como se pudo apreciar en esta entrada, la realidad es tan compleja que para entenderla se crearon muchas técnicas de estudio a lo largo de la historia, las cuales, nunca fueron suficientes y fueron reinventadas constantemente. Esto no cambia en nuestros días y, somos testigos de cómo estas propuestas se llevan a cabo a partir de los sistemas informáticos, principalmente. En ese sentido, la idea de hipertexto, concebida desde la literatura como una penetrante ficción o, puesta en práctica, de manera esforzada, desde la archivística, a pesar de las limitantes del papel como soporte informático principal de la época, se presenta ahora de forma hegemónica desde las tecnologías de la información para gestionar el conocimiento compartido. Sin embargo, en paralelo, amenaza esa hegemonía la hipermedia, desde la propuesta de la realidad virtual o metaverso, que si bien, ahora constituye todavía una ficción, bien podría jugar un papel protagónico en el futuro, en parte, gracias a los siguientes avances en cuanto a inteligencia artificial.
Volviendo al foco del tema, hay cuestiones muy profundas que deben analizarse para evaluar cuál es el rol del hipertexto en nuestra vida cotidiana y, para lograr eso, quiero volver a los cuentos de Borges, aquellos considerados precursores del concepto de hipertexto. Anteriormente, yo, ponía en duda el postulado de que Borges no produjo una ficción hipertextual por las limitaciones tecnológicas de su época y, aunque, claramente, Borges presenta esta idea como una genialidad, también la retrata como propensa a la incomprensión e, incluso, al desdén. El hecho de que este tipo de literatura, una vez superadas las limitaciones tecnológicas, gracias a los ordenadores modernos distribuidos masivamente en la sociedad, no haya sido exitosa, en comparación a otros géneros, digamos, más "clásicos" o, innovaciones bajo el concepto de hipermedia, probablemente refuerza la idea de que Borges no encontraría, incluso ahora, esta idea como buena. Como se mostró, el hipertexto parece apropiado más bien para el ámbito académico y productivo y, esto queda demostrado por el hecho de que, más que haber fantaseado con ello, se lo haya implementado, al menos desde el ámbito de la bibliotecología, donde el zettelkasten alemán, un claro hipertexto en formato escrito, fue llevado a cabo en una etapa pre-digital, basándose en una tradición que ya venía aproximándose a esta idea, al menos desde la Ilustración. Esta técnica fue llevada a su extremo, en el siglo XX, además, de forma analógica, por el sociólogo Niklas Luhmann, de cuyos ejercicios surge su teoría de sistemas, la cual, debe ser analizada con merecido cuidado.
Recordemos que el personaje Ts'ui Pên, en el cuento de Borges, se había propuesto crear un relato que demuestre las bifurcaciones del tiempo y, no así del espacio, como inicialmente se creyó, lo que devenía en textos que representaban un enjambre de posibilidades, de sucesos y, personajes, que enredaría la comprensión de la mayoría de las personas. Pues, el zettelkasten de Niklas Luhmann, probablemente, es uno de los ejercicios reales que más se acerca a ese objeto fantástico, pero en este caso, Luhmann, no se propuso representar las bifurcaciones del tiempo, al modo de la fantasía de Borges, que probablemente tomó está idea de sus lecturas de la teoría de la relatividad, sino, la causalidad circular o autopoiesis. La pregunta que surge aquí, luego de hacer esa descabellada comparación entre la labor de un personaje ficticio y uno real, es, ¿hasta qué punto la construcción de este conocimiento sistemático, en el mundo real, desemboca en un desenlace similar al ocurrido en el cuento? Debe recordarse que, en el cuento, el objeto creado por Ts'ui Pên, a pesar de ser incomprendido, es de una mística increíble, ya que probablemente se apropia del devenir real, que, para este caso ficticio, sería el desenlace del cuento.
Este es un debate filosófico antiguo: ¿hasta qué punto las ideas humanas corresponden con la realidad, sin intervención de los sesgos ligados a la naturaleza de su percepción? Tomando en cuenta que la lógica humana es una lógica, históricamente construida, además, sobre la base de las percepciones previas de otros y, los sentidos, están limitados por nuestra fisiología (recordemos que los sentidos de otros seres son más agudos), el conocimiento se construye con alguna correspondencia a la realidad y, esa correspondencia, por definición, es imperfecta, ya que la mente del sujeto nunca será el objeto, sino elementos distintos. Y si bien, hay objetivos que con la acumulación de agudas observaciones, sumadas a una voluntad de hierro, pueden llegar a materializarse, sin embargo, también hay casos que nos muestran cuan alejados estamos de comprender ciertas cosas. Quiero citar, como ejemplo del primer caso, al alunizaje acontecido el 20 de julio de 1969, por la misión Apolo 11 y; como muestra del segundo, a los problemas que representa la mecánica cuántica para el conocimiento físico que permitió, precisamente, el logro del primer ejemplo.
Creo que con el hipertexto pasa algo parecido, si bien, es un constructo humano de lo más útil, fantasías como las de Borges pueden estarle otorgando una proporción que no le corresponde en la realidad. En este sentido, podemos modificar la anterior pregunta de la siguiente manera: ¿en qué medida un hipertexto construido de forma personal o, incluso, de forma colaborativa, llega a reflejar la realidad, sin distorsionarla con elementos propios de la historia personal y colectiva? Ante ese cuestionante, me parece que la frase que acuñó el psicólogo Serge André para describir una novela que había escrito, basándose en su propia vida, arroja cierta luz:
"[la novela es] autobiográfica al cien por ciento, pero con novecientos por ciento de ficción".
Descripción que la escritora Natalia Zito, autora de la fuente de donde extraje la frase, interpretaría de la siguiente forma, con el objetivo de reflexionar sobre el proceso de escribir:
Si hay alguna posibilidad de pensar la potencia de la escritura, yo la ubicaría ahí: en ese novecientos por ciento, en esa operación que es un poco oficio, un poco juego y algo de traición, que implica tergiversar los recuerdos, exagerar, distorsionar e inventar. La función salvadora de la escritura está en la renovación del lenguaje. Parafraseando a Pizarnik, en el barco que parte del autor, llevándoselo.
Mi intención al insertar aquí estas citas no es negar la posibilidad del planteamiento de un conocimiento científico útil, sino, proponer que es bueno aceptar las limitantes que impone la realidad a esas ideas, que al fin y al cabo, son constructos humanos a los que suele catalogarse como "objetivos", así, sin una pizca de humildad e, incluso por sus propios autores 🥹. Y para el caso de la generación de un hipertexto descomunal, con ramas académicas, productivas e incluso literarias, esto aplica a la perfección: hay aspectos de la realidad que se pueden controlar y otros que no y, creo que la clave está en identificar ambos. En ese sentido, por más ramificado que esté ese mapa de tareas y, elaborado sobre la base de horas de racionalidad sistemática, podrá, quizás, ser útil a ciertos logros, pero, al no ser "objetivo", necesariamente, tarde o temprano, arribará la improvisación y quizás, incluso, el caos y, esto está bien, es inevitable, desde siempre y, tal vez, para siempre. Por ello, el sabio Epicteto escribió: "no te inquietes por lo que no depende de ti".
Así, podría instalarme Anytype u otra aplicación tipo Notion y, crear el zettelkasten más grande del mundo, pero ello no impediría que lo tome como lo que realmente es: un buen y, noble intento más, una pequeña perspectiva añadida sobre el infinito, una, insignificante... ficción.
 Imagen generada con Playground AI de acuerdo sus
Imagen generada con Playground AI de acuerdo sus  Captura de pantalla de documento ODT
Captura de pantalla de documento ODT Captura de pantalla de documento DOCX, importado de ODT
Captura de pantalla de documento DOCX, importado de ODT
 Imagen de Elf-Moondance.
Imagen de Elf-Moondance. {kind=link}